|
近日,计算机系自然语言处理实验室研究团队与北京大学化学与分子工程学院朱戎团队合作,在化学合成指令的自动转写方面取得新进展。研究团队提出了化学合成指令的双向转写任务,对自然语言描述和机器可执行操作指令之间的转化过程进行了标准定义与数据标注。该工作搭建了文献描述与合成指令之间的双向转写系统,并且提出多细粒度知识注入方法,针对不同层级设计预训练任务,让语言模型更高效精准地学习化学合成专业知识。在相关数据集上的实验表明,该工作构建的模型能够在合成指令双向转写上全面超过GPT-3.5系列模型表现,使用该系统辅助转写的人工效率提高40%以上。
以GPT-4为代表的大语言模型已在各学科中展现出了强大的专业知识学习能力,成为“科学人工智能”(AI for Science)方向令人瞩目的热门话题。在合成化学领域,人工智能驱动的自动化实验平台是近年来的研究热点,有望替代人类研究者开展枯燥重复的甚至有危险的合成实验。而实现自动化学合成的关键是利用好现在广泛存在于各类文献中的化学合成实验。然而,已有的化学合成实验流程均以自然语言的非结构化形式记录在文献和数据库中,这些散落在文献中的合成流程的自然语言描述与机器可执行的指令之间,存在着巨大的形式和语义鸿沟,需要人力转写才能用于人工智能自动化实验。研制化学合成指令转写系统,实现海量自然语言实验记录向机器合成指令的高效转化,支持完成更多化学合成的自动化实验,具有重要的研究意义和应用价值。
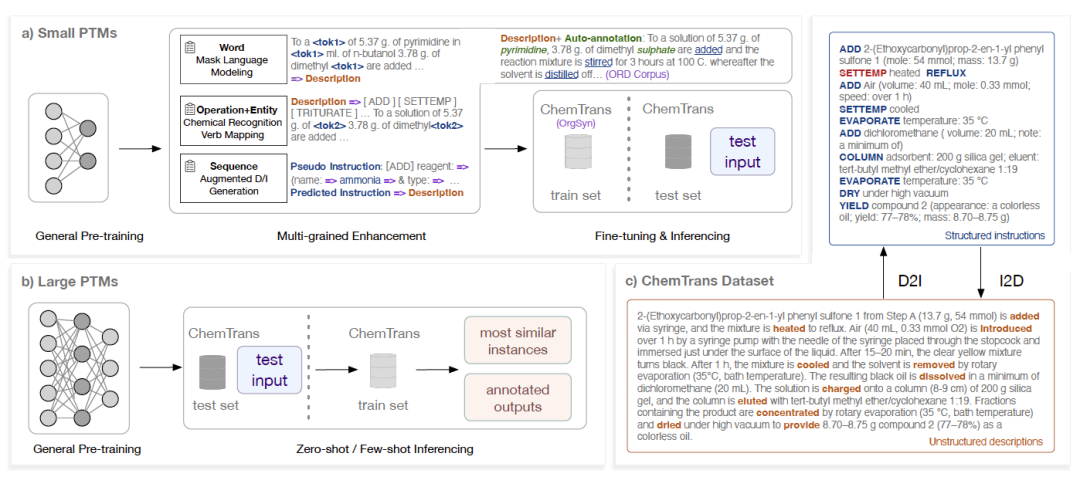
合成指令双向转写的工作流程示意图
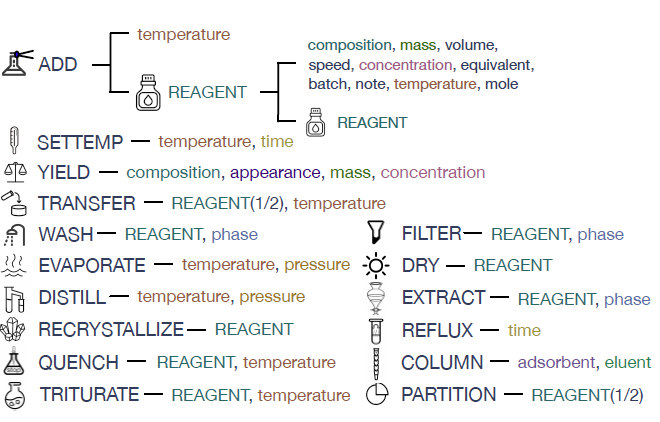
合成指令的层次化框架
该研究结合大量化学文献的统计结果和专家知识,制定了化学合成指令的层次化框架,包含16种元操作和18种参数;参考序列匹配任务的评测方式,设计了SeqMatch指标,对合成指令转写任务的标准化评测具有重要作用;提出了针对合成化学的多细粒度知识增强预训练方法,在单词级、化学实体级、元操作级和合成序列级,分别设计了掩码学习、实体识别、操作映射、序列预测等多种预训练任务,赋予模型以当前任务所需的丰富的化学知识。
该系统相较于其他类似工作可以实现更完备而准确的合成指令生成,也能根据指令撰写流畅自然的合成化学文献段落。该工作还探索了当前模型的更多可能用途,例如针对特定合成指令预测下一步骤、根据转写表现筛选出更简明规范的文本等。这些实验表明,预训练模型可以提供面向通用合成规律以及合成描述规范性的洞察。

本系统与同类系统的指令转写表现对比

本系统与GPT-3.5系列模型在双向转写任务上的表现对比
8月24日,研究成果在英国皇家化学会综合性旗舰期刊《化学科学》(Chemical Science)以“人类可读的合成描述与机器可执行的指令之间的转写:最新预训练技术的应用”(Transcription between human-readable synthetic descriptions and machine-executable instructions: an application of the latest pre-training technology)为题发表。这是该课题组继“桥接分子结构与生医文本的预训练语言模型”(Nature Communications, 2022)之后,在生化与自然语言处理交叉领域的又一重要进展。
清华大学计算机系副教授刘知远、北京大学化学与分子工程学院研究员朱戎为文章的通讯作者。清华大学计算机系博士生曾哲妮、丁宁,北京大学本科生聂翊宸为文章的共同第一作者。该研究得到国家自然科学基金委和国家重点研发计划项目的资助。
论文链接:
https://doi.org/10.1039/D3SC02483K
清华大学

|